(Redirected from Compound gamma distribution)
Probability distribution
Beta prime
Probability density function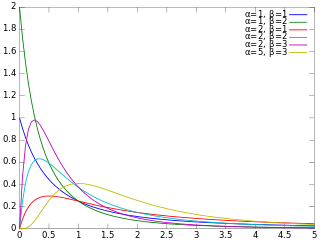 |
Cumulative distribution function |
| Parameters |
 shape (real) shape (real)
 shape (real) shape (real) |
|---|
| Support |
 |
|---|
| PDF |
 |
|---|
| CDF |
 where where  is the incomplete beta function is the incomplete beta function |
|---|
| Mean |
 if if  |
|---|
| Mode |
 |
|---|
| Variance |
 if if  |
|---|
| Skewness |
 if if  |
|---|
| Excess kurtosis |
 if if  |
|---|
| Entropy |
 where where  is the digamma function. is the digamma function. |
|---|
| MGF |
Does not exist |
|---|
| CF |
 |
|---|
In probability theory and statistics, the beta prime distribution (also known as inverted beta distribution or beta distribution of the second kind) is an absolutely continuous probability distribution. If  has a beta distribution, then the odds
has a beta distribution, then the odds  has a beta prime distribution.
has a beta prime distribution.
Definitions
Beta prime distribution is defined for  with two parameters α and β, having the probability density function:
with two parameters α and β, having the probability density function:

where B is the Beta function.
The cumulative distribution function is

where I is the regularized incomplete beta function.
While the related beta distribution is the conjugate prior distribution of the parameter of a Bernoulli distribution expressed as a probability, the beta prime distribution is the conjugate prior distribution of the parameter of a Bernoulli distribution expressed in odds. The distribution is a Pearson type VI distribution.
The mode of a variate X distributed as  is
is  .
Its mean is if (if
.
Its mean is if (if  the mean is infinite, in other words it has no well defined mean) and its variance is if .
the mean is infinite, in other words it has no well defined mean) and its variance is if .
For  , the k-th moment
, the k-th moment  is given by
is given by

For  with
with  this simplifies to
this simplifies to

The cdf can also be written as

where  is the Gauss's hypergeometric function 2F1 .
is the Gauss's hypergeometric function 2F1 .
Alternative parameterization
The beta prime distribution may also be reparameterized in terms of its mean μ > 0 and precision ν > 0 parameters ( p. 36).
Consider the parameterization μ = α/(β − 1) and ν = β − 2, i.e., α = μ(1 + ν) and
β = 2 + ν. Under this parameterization
E = μ and Var = μ(1 + μ)/ν.
Generalization
Two more parameters can be added to form the generalized beta prime distribution  :
:
 shape (real)
shape (real) scale (real)
scale (real)
having the probability density function:

with mean

and mode

Note that if p = q = 1 then the generalized beta prime distribution reduces to the standard beta prime distribution.
This generalization can be obtained via the following invertible transformation. If  and
and  for
for  , then
, then  .
.
Compound gamma distribution
The compound gamma distribution is the generalization of the beta prime when the scale parameter, q is added, but where p = 1. It is so named because it is formed by compounding two gamma distributions:

where  is the gamma pdf with shape
is the gamma pdf with shape  and inverse scale
and inverse scale  .
.
The mode, mean and variance of the compound gamma can be obtained by multiplying the mode and mean in the above infobox by q and the variance by q.
Another way to express the compounding is if  and
and  , then
, then  . This gives one way to generate random variates with compound gamma, or beta prime distributions. Another is via the ratio of independent gamma variates, as shown below.
. This gives one way to generate random variates with compound gamma, or beta prime distributions. Another is via the ratio of independent gamma variates, as shown below.
Properties
- If
 then
then  .
.
- If
 , and
, and  , then
, then  .
.
- If then
 .
.

Related distributions
- If
 , then
, then  . This property can be used to generate beta prime distributed variates.
. This property can be used to generate beta prime distributed variates.
- If , then
 . This is a corollary from the property above.
. This is a corollary from the property above.
- If
 has an F-distribution, then
has an F-distribution, then  , or equivalently,
, or equivalently,  .
.
- For gamma distribution parametrization I:
- If
 are independent, then
are independent, then  . Note
. Note  are all scale parameters for their respective distributions.
are all scale parameters for their respective distributions.
- For gamma distribution parametrization II:
- If
 are independent, then
are independent, then  . The
. The  are rate parameters, while
are rate parameters, while  is a scale parameter.
is a scale parameter.
- If
 and
and  , then
, then  . The are rate parameters for the gamma distributions, but
. The are rate parameters for the gamma distributions, but  is the scale parameter for the beta prime.
is the scale parameter for the beta prime.
 the Dagum distribution
the Dagum distribution the Singh–Maddala distribution.
the Singh–Maddala distribution. the log logistic distribution.
the log logistic distribution.- The beta prime distribution is a special case of the type 6 Pearson distribution.
- If X has a Pareto distribution with minimum
 and shape parameter
and shape parameter  , then
, then  .
.
- If X has a Lomax distribution, also known as a Pareto Type II distribution, with shape parameter and scale parameter
 , then
, then  .
.
- If X has a standard Pareto Type IV distribution with shape parameter and inequality parameter
 , then
, then  , or equivalently,
, or equivalently,  .
.
- The inverted Dirichlet distribution is a generalization of the beta prime distribution.
- If , then
 has a generalized logistic distribution. More generally, if , then has a scaled and shifted generalized logistic distribution.
has a generalized logistic distribution. More generally, if , then has a scaled and shifted generalized logistic distribution.
- If
 , then
, then  follows a Cauchy distribution, which is equivalent to a student-t distribution with the degrees of freedom of 1.
follows a Cauchy distribution, which is equivalent to a student-t distribution with the degrees of freedom of 1.
Notes
- ^ Johnson et al (1995), p 248
- Bourguignon, M.; Santos-Neto, M.; de Castro, M. (2021). "A new regression model for positive random variables with skewed and long tail". Metron. 79: 33–55. doi:10.1007/s40300-021-00203-y. S2CID 233534544.
- Dubey, Satya D. (December 1970). "Compound gamma, beta and F distributions". Metrika. 16: 27–31. doi:10.1007/BF02613934. S2CID 123366328.
References
- Johnson, N.L., Kotz, S., Balakrishnan, N. (1995). Continuous Univariate Distributions, Volume 2 (2nd Edition), Wiley. ISBN 0-471-58494-0
- Bourguignon, M.; Santos-Neto, M.; de Castro, M. (2021), "A new regression model for positive random variables with skewed and long tail", Metron, 79: 33–55, doi:10.1007/s40300-021-00203-y, S2CID 233534544
Categories:

