| Information theory |
|---|
 |
In information theory, the cross-entropy between two probability distributions and , over the same underlying set of events, measures the average number of bits needed to identify an event drawn from the set when the coding scheme used for the set is optimized for an estimated probability distribution , rather than the true distribution .
 and
and  , over the same underlying set of events, measures the average number of
, over the same underlying set of events, measures the average number of Definition
The cross-entropy of the distribution relative to a distribution over a given set is defined as follows:

where is the expected value operator with respect to the distribution .
 is the
is the The definition may be formulated using the Kullback–Leibler divergence , divergence of from (also known as the relative entropy of with respect to ).
 , divergence of
, divergence of

where is the entropy of .
 is the
is the For discrete probability distributions and with the same support , this means
 , this means
, this means
(Eq.1)
 (Eq.1)
(Eq.1)
The situation for continuous distributions is analogous. We have to assume that and are absolutely continuous with respect to some reference measure (usually is a Lebesgue measure on a Borel σ-algebra). Let and be probability density functions of and with respect to . Then
 (usually
(usually  and
and  be probability density functions of
be probability density functions of

and therefore
(Eq.2)
 (Eq.2)
(Eq.2)
NB: The notation is also used for a different concept, the joint entropy of and .
 is also used for a different concept, the
is also used for a different concept, the Motivation
In information theory, the Kraft–McMillan theorem establishes that any directly decodable coding scheme for coding a message to identify one value out of a set of possibilities can be seen as representing an implicit probability distribution over , where is the length of the code for in bits. Therefore, cross-entropy can be interpreted as the expected message-length per datum when a wrong distribution is assumed while the data actually follows a distribution . That is why the expectation is taken over the true probability distribution and not Indeed the expected message-length under the true distribution is
 out of a set of possibilities
out of a set of possibilities  can be seen as representing an implicit probability distribution
can be seen as representing an implicit probability distribution  over
over  is the length of the code for
is the length of the code for  Indeed the expected message-length under the true distribution
Indeed the expected message-length under the true distribution



Estimation
There are many situations where cross-entropy needs to be measured but the distribution of is unknown. An example is language modeling, where a model is created based on a training set , and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example, is the true distribution of words in any corpus, and is the distribution of words as predicted by the model. Since the true distribution is unknown, cross-entropy cannot be directly calculated. In these cases, an estimate of cross-entropy is calculated using the following formula:
 , and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example,
, and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example,

where is the size of the test set, and is the probability of event estimated from the training set. In other words, is the probability estimate of the model that the i-th word of the text is . The sum is averaged over the words of the test. This is a Monte Carlo estimate of the true cross-entropy, where the test set is treated as samples from .
 is the size of the test set, and
is the size of the test set, and  is the probability of event
is the probability of event  estimated from the training set. In other words,
estimated from the training set. In other words,  is the probability estimate of the model that the i-th word of the text is
is the probability estimate of the model that the i-th word of the text is  .
.
Relation to maximum likelihood
The cross entropy arises in classification problems when introducing a logarithm in the guise of the log-likelihood function.
The section is concerned with the subject of estimation of the probability of different possible discrete outcomes. To this end, denote a parametrized family of distributions by , with subject to the optimization effort. Consider a given finite sequence of values from a training set, obtained from conditionally independent sampling. The likelihood assigned to any considered parameter of the model is then given by the product over all probabilities . Repeated occurrences are possible, leading to equal factors in the product. If the count of occurrences of the value equal to (for some index ) is denoted by , then the frequency of that value equals . Denote the latter by , as it may be understood as empirical approximation to the probability distribution underlying the scenario. Further denote by the perplexity, which can be seen to equal by the calculation rules for the logarithm, and where the product is over the values without double counting. So or Since the logarithm is a monotonically increasing function, it does not affect extremization. So observe that the likelihood maximization amounts to minimization of the cross-entropy.
 , with
, with  subject to the optimization effort. Consider a given finite sequence of
subject to the optimization effort. Consider a given finite sequence of  .
Repeated occurrences are possible, leading to equal factors in the product. If the count of occurrences of the value equal to
.
Repeated occurrences are possible, leading to equal factors in the product. If the count of occurrences of the value equal to  ) is denoted by
) is denoted by  , then the frequency of that value equals
, then the frequency of that value equals  . Denote the latter by
. Denote the latter by  , as it may be understood as empirical approximation to the probability distribution underlying the scenario. Further denote by
, as it may be understood as empirical approximation to the probability distribution underlying the scenario. Further denote by  the
the  by the
by the  or
or
 Since the logarithm is a
Since the logarithm is a Cross-entropy minimization
Main article: Cross-entropy methodCross-entropy minimization is frequently used in optimization and rare-event probability estimation. When comparing a distribution against a fixed reference distribution , cross-entropy and KL divergence are identical up to an additive constant (since is fixed): According to the Gibbs' inequality, both take on their minimal values when , which is for KL divergence, and for cross-entropy. In the engineering literature, the principle of minimizing KL divergence (Kullback's "Principle of Minimum Discrimination Information") is often called the Principle of Minimum Cross-Entropy (MCE), or Minxent.
 , which is
, which is  for KL divergence, and
for KL divergence, and  for cross-entropy. In the engineering literature, the principle of minimizing KL divergence (Kullback's "
for cross-entropy. In the engineering literature, the principle of minimizing KL divergence (Kullback's "However, as discussed in the article Kullback–Leibler divergence, sometimes the distribution is the fixed prior reference distribution, and the distribution is optimized to be as close to as possible, subject to some constraint. In this case the two minimizations are not equivalent. This has led to some ambiguity in the literature, with some authors attempting to resolve the inconsistency by restating cross-entropy to be , rather than . In fact, cross-entropy is another name for relative entropy; see Cover and Thomas and Good. On the other hand, does not agree with the literature and can be misleading.
Cross-entropy loss function and logistic regression
Cross-entropy can be used to define a loss function in machine learning and optimization. Mao, Mohri, and Zhong (2023) give an extensive analysis of the properties of the family of cross-entropy loss functions in machine learning, including theoretical learning guarantees and extensions to adversarial learning. The true probability is the true label, and the given distribution is the predicted value of the current model. This is also known as the log loss (or logarithmic loss or logistic loss); the terms "log loss" and "cross-entropy loss" are used interchangeably.
 is the true label, and the given distribution
is the true label, and the given distribution  is the predicted value of the current model. This is also known as the log loss (or logarithmic loss or
is the predicted value of the current model. This is also known as the log loss (or logarithmic loss or More specifically, consider a binary regression model which can be used to classify observations into two possible classes (often simply labelled and ). The output of the model for a given observation, given a vector of input features , can be interpreted as a probability, which serves as the basis for classifying the observation. In logistic regression, the probability is modeled using the logistic function where is some function of the input vector , commonly just a linear function. The probability of the output is given by where the vector of weights is optimized through some appropriate algorithm such as gradient descent. Similarly, the complementary probability of finding the output is simply given by
 ). The output of the model for a given observation, given a vector of input features
). The output of the model for a given observation, given a vector of input features  where
where  is some function of the input vector
is some function of the input vector  is given by
is given by
 where the vector of weights
where the vector of weights  is optimized through some appropriate algorithm such as
is optimized through some appropriate algorithm such as  is simply given by
is simply given by

Having set up our notation, and , we can use cross-entropy to get a measure of dissimilarity between and :
 and
and  , we can use cross-entropy to get a measure of dissimilarity between
, we can use cross-entropy to get a measure of dissimilarity between 
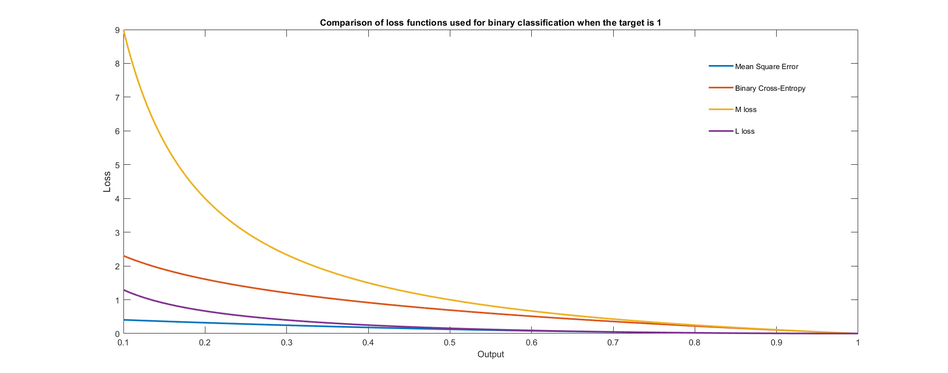
Plot shows different loss functions that can be used to train a binary classifier. Only the case where the target output is 1 is shown. It is observed that the loss is zero when the target is equal to the output and increases as the output becomes increasingly incorrect.

Logistic regression typically optimizes the log loss for all the observations on which it is trained, which is the same as optimizing the average cross-entropy in the sample. Other loss functions that penalize errors differently can be also used for training, resulting in models with different final test accuracy. For example, suppose we have samples with each sample indexed by . The average of the loss function is then given by:
 . The average of the loss function is then given by:
. The average of the loss function is then given by:

where , with the logistic function as before.
 , with
, with  the logistic function as before.
the logistic function as before.
The logistic loss is sometimes called cross-entropy loss. It is also known as log loss. (In this case, the binary label is often denoted by {−1,+1}.)
Remark: The gradient of the cross-entropy loss for logistic regression is the same as the gradient of the squared-error loss for linear regression. That is, define



Then we have the result

The proof is as follows. For any , we have
 , we have
, we have






In a similar way, we eventually obtain the desired result.
Amended cross-entropy
It may be beneficial to train an ensemble of models that have diversity, such that when they are combined, their predictive accuracy is augmented. Assuming a simple ensemble of classifiers is assembled via averaging the outputs, then the amended cross-entropy is given by where is the cost function of the classifier, is the output probability of the classifier, is the true probability to be estimated, and is a parameter between 0 and 1 that defines the 'diversity' that we would like to establish among the ensemble. When we want each classifier to do its best regardless of the ensemble and when we would like the classifier to be as diverse as possible.
 classifiers is assembled via averaging the outputs, then the amended cross-entropy is given by
classifiers is assembled via averaging the outputs, then the amended cross-entropy is given by
 where
where  is the cost function of the
is the cost function of the  classifier,
classifier,  is the output probability of the
is the output probability of the  is a parameter between 0 and 1 that defines the 'diversity' that we would like to establish among the ensemble. When
is a parameter between 0 and 1 that defines the 'diversity' that we would like to establish among the ensemble. When  we want each classifier to do its best regardless of the ensemble and when
we want each classifier to do its best regardless of the ensemble and when  we would like the classifier to be as diverse as possible.
we would like the classifier to be as diverse as possible.
See also
- Cross-entropy method
- Logistic regression
- Conditional entropy
- Kullback–Leibler distance
- Maximum-likelihood estimation
- Mutual information
- Perplexity
References
- Thomas M. Cover, Joy A. Thomas, Elements of Information Theory, 2nd Edition, Wiley, p. 80
- I. J. Good, Maximum entropy for hypothesis formulation, especially for multidimensional contingency tables, Ann. of Math. Statistics, 1963
- Anqi Mao, Mehryar Mohri, Yutao Zhong. Cross-entropy loss functions: Theoretical analysis and applications. ICML 2023. https://arxiv.org/pdf/2304.07288.pdf
- The Mathematics of Information Coding, Extraction and Distribution, by George Cybenko, Dianne P. O'Leary, Jorma Rissanen, 1999, p. 82
- Probability for Machine Learning: Discover How To Harness Uncertainty With Python, Jason Brownlee, 2019, p. 220: "Logistic loss refers to the loss function commonly used to optimize a logistic regression model. It may also be referred to as logarithmic loss (which is confusing) or simply log loss."
- sklearn.metrics.log_loss
- Noel, Mathew; Banerjee, Arindam; D, Geraldine Bessie Amali; Muthiah-Nakarajan, Venkataraman (March 17, 2023). "Alternate loss functions for classification and robust regression can improve the accuracy of artificial neural networks". arXiv:2303.09935 .
- Murphy, Kevin (2012). Machine Learning: A Probabilistic Perspective. MIT. ISBN 978-0262018029.
- Shoham, Ron; Permuter, Haim H. (2019). "Amended Cross-Entropy Cost: An Approach for Encouraging Diversity in Classification Ensemble (Brief Announcement)". In Dolev, Shlomi; Hendler, Danny; Lodha, Sachin; Yung, Moti (eds.). Cyber Security Cryptography and Machine Learning – Third International Symposium, CSCML 2019, Beer-Sheva, Israel, June 27–28, 2019, Proceedings. Lecture Notes in Computer Science. Vol. 11527. Springer. pp. 202–207. doi:10.1007/978-3-030-20951-3_18. ISBN 978-3-030-20950-6.
- Shoham, Ron; Permuter, Haim (2020). "Amended Cross Entropy Cost: Framework For Explicit Diversity Encouragement". arXiv:2007.08140 .
Further reading
- de Boer, Kroese, D.P., Mannor, S. and Rubinstein, R.Y. (2005). A tutorial on the cross-entropy method. Annals of Operations Research 134 (1), 19–67.