| Urdu alphabet اُردُو حُرُوفِ تَہَجِّی Urdū ḥurūf-i tahajjī | |
|---|---|
 The word Urdū written in the Urdu alphabet The word Urdū written in the Urdu alphabet | |
| Script type | Abjad |
| Official script | |
| Languages | |
| Related scripts | |
| Parent systems | Egyptian hieroglyphs |
| Unicode | |
| Unicode range | U+0600 to U+06FF U+0750 to U+077F |
| This article contains phonetic transcriptions in the International Phonetic Alphabet (IPA). For an introductory guide on IPA symbols, see Help:IPA. For the distinction between , / / and ⟨ ⟩, see IPA § Brackets and transcription delimiters. | |
| Urdu alphabet |
|---|
| ا (آ) ب پ ت ٹ ث ج چ ح خ د ڈ ذ ر ڑ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ل م ن (ں) و ہ (ھ) ء ی ے |
|
Extended Perso-Arabic script |
| Writing systems |
|---|
 |
| Abjad |
| Arabic Hebrew |
| Abugida |
| Canadian syllabics Ethiopic North Indic South Indic Thaana |
| Alphabetical |
| Armenian Cyrillic Georgian Greek Latin Mongolian Neo-Tifinagh Osage |
| Logographic |
| Hanzi |
| Syllabic |
| Cherokee |
| Hybrids |
| Japanese (Logographic and syllabic) Hangul (Alphabetic and syllabic) |
The Urdu alphabet (Urdu: اُردُو حُرُوفِ تَہَجِّی, romanized: urdū ḥurūf-i tahajjī) is the right-to-left alphabet used for writing Urdu. It is a modification of the Persian alphabet, which itself is derived from the Arabic script. It has co-official status in the republics of Pakistan, India and South Africa. The Urdu alphabet has up to 39 or 40 distinct letters with no distinct letter cases and is typically written in the calligraphic Nastaʿlīq script, whereas Arabic is more commonly written in the Naskh style.
Usually, bare transliterations of Urdu into the Latin alphabet (called Roman Urdu) omit many phonemic elements that have no equivalent in English or other languages commonly written in the Latin script.
History
The standard Urdu script is a modified version of the Perso-Arabic script and has its origins in the 13th century Iran. It is also related to Shahmukhi, used for the Punjabi language varieties in Punjab, Pakistan. It is closely related to the development of the Nastaʻliq style of Perso-Arabic script.
Despite the invention of the Urdu typewriter in 1911, Urdu newspapers continued to publish prints of handwritten scripts by calligraphers known as katibs or khush-navees until the late 1980s. The Pakistani national newspaper Daily Jang was the first Urdu newspaper to use Nastaʿlīq computer-based composition. There are efforts under way to develop more sophisticated and user-friendly Urdu support on computers and the internet. Nowadays, nearly all Urdu newspapers, magazines, journals, and periodicals are composed on computers with Urdu software programs.
Other than the Indian subcontinent, the Urdu script is also used by Pakistan's large diaspora, including in the United Kingdom, the United Arab Emirates, the United States, Canada, Saudi Arabia and other places.
Nastaliq

Urdu is written in the Nastaliq style (Persian: نستعلیق Nastaʿlīq). The Nastaliq calligraphic writing style began as a Persian mixture of the Naskh and Ta'liq scripts. After the Muslim conquest of the Indian subcontinent, Nastaʻliq became the preferred writing style for Urdu. It is the dominant style in Pakistan and many Urdu writers elsewhere in the world use it. Nastaʿlīq is more cursive and flowing than its Naskh counterpart.
In the Arabic alphabet, and many others derived from it, letters are regarded as having two or three general forms each, based on their position in the word (though Arabic calligraphy can add a great deal of complexity). But the Nastaliq style in which Urdu is written uses more than three general forms for many letters, even in simple non-decorative documents.
Alphabet
The Urdu script is an abjad script derived from the modern Persian script, which is itself a derivative of the Arabic script. As an abjad, the Urdu script only shows consonants and long vowels; short vowels can only be inferred by the consonants' relation to each other. While this type of script is convenient in Semitic languages like Arabic and Hebrew, whose consonant roots are the key of the sentence, Urdu is an Indo-European language, which requires more precision in vowel sound pronunciation, hence necessitating more memorisation. The number of letters in the Urdu alphabet is somewhat ambiguous and debated.
Letter names and phonemes
| Name | Forms | IPA | Romanization | Unicode | Order | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Urdu Roman Urdu |
Isolated | Final | Medial | Initial | ALA-LC | Hunterian | |||||
| الف alif |
ا | ـا | /ɑː/, /ʔ/, silent | ā, – | ā, – | U+0627 | 1 | 1 | 1 | ||
| بے bē |
ب | ـب | ـبـ | بـ | /b/ | b | b | U+0628 | 2 | 2 | 2 |
| پے pē |
پ | ـپ | ـپـ | پـ | /p/ | p | p | U+067E | 3 | 3 | 3 |
| تے tē |
ت | ـت | ـتـ | تـ | /t/ | t | t | U+062A | 4 | 4 | 4 |
| ٹے ṭē |
ٹ | ـٹ | ـٹـ | ٹـ | /ʈ/ | ṭ | t | U+0679 | 5 | 5 | 5 |
| ثے s̱ē |
ث | ـث | ـثـ | ثـ | /s/ | s̱ | s | U+062B | 6 | 6 | 6 |
| جيم jīm |
ج | ـج | ـجـ | جـ | /d͡ʒ/ | j | j | U+062C | 7 | 7 | 7 |
| چے cē |
چ | ـچ | ـچـ | چـ | /t͡ʃ/ | c | ch | U+0686 | 8 | 8 | 8 |
| بڑی حے baṛī ḥē |
ح | ـح | ـحـ | حـ | /ɦ/ | ḥ | h | U+062D | 9 | 9 | 9 |
| حائے حطی ḥā'e huttī | |||||||||||
| حائے مہملہ ḥā'e muhmala | |||||||||||
| خے k͟hē |
خ | ـخ | ـخـ | خـ | /x/ | k͟h | kh | U+062E | 10 | 10 | 10 |
| دال dāl |
د | ـد | /d/ | d | d | U+062F | 11 | 11 | 11 | ||
| ڈال ḍāl |
ڈ | ـڈ | /ɖ/ | ḍ | d | U+0688 | 12 | 12 | 12 | ||
| ذال ẕāl |
ذ | ـذ | /z/ | ẕ | z | U+0630 | 13 | 13 | 13 | ||
| رے rē |
ر | ـر | /r/ | r | r | U+0631 | 14 | 14 | 14 | ||
| ڑے ṛē |
ڑ | ـڑ | /ɽ/ |
ṛ | r | U+0691 | 15 | 15 | 15 | ||
| زے zē |
ز | ـز | /z/ | z | z | U+0632 | 16 | 16 | 16 | ||
| ژے zhē |
ژ | ـژ | /ʒ/ |
zh | zh | U+0698 | 17 | 17 | 17 | ||
| سین sīn |
س | ـس | ـسـ | سـ | /s/ | s | s | U+0633 | 18 | 18 | 18 |
| شین shīn |
ش | ـش | ـشـ | شـ | /ʃ/ | sh | sh | U+0634 | 19 | 19 | 19 |
| صاد ṣwād |
ص | ـص | ـصـ | صـ | /s/ | ṣ | s | U+0635 | 20 | 20 | 20 |
| ضاد ẓwād |
ض | ـض | ـضـ | ضـ | /z/ | ẓ | z | U+0636 | 21 | 21 | 21 |
| طوے t̤oʼē |
ط | ـط | ـطـ | طـ | /t/ | t̤ | t | U+0637 | 22 | 22 | 22 |
| ظوے z̤oʼē |
ظ | ـظ | ـظـ | ظـ | /z/ | z̤ | z | U+0638 | 23 | 23 | 23 |
| عین ʻain |
ع | ـع | ـعـ | عـ | /ɑː/, /oː/, /eː/, /ʔ/, /ʕ/, silent |
ʻ | ʻ |
U+0639 | 24 | 24 | 24 |
| غین g͟hain |
غ | ـغ | ـغـ | غـ | /ɣ/ | g͟h | gh | U+063A | 25 | 25 | 25 |
| فے fē |
ف | ـف | ـفـ | فـ | /f/ | f | f | U+0641 | 26 | 26 | 26 |
| قاف qāf |
ق | ـق | ـقـ | قـ | /q/ | q | q | U+0642 | 27 | 27 | 27 |
| کاف kāf |
ک | ـک | ـکـ | کـ | /k/ | k | k | U+06A9 | 28 | 28 | 28 |
| گاف gāf |
گ | ـگ | ـگـ | گـ | /ɡ/ | g | g | U+06AF | 29 | 29 | 29 |
| لام lām |
ل | ـل | ـلـ | لـ | /l/ | l | l | U+0644 | 30 | 30 | 30 |
| میم mīm |
م | ـم | ـمـ | مـ | /m/ | m | m | U+0645 | 31 | 31 | 31 |
| نون nūn |
ن | ـن | ـنـ | نـ | /n/, /ɲ/, /ɳ/, /ŋ/ |
n | n | U+0646 | 32 | 32 | 32 |
| نون غنّہ nūn g͟hunnā |
ں ٘ |
ـں | ـںـ | ںـ | / ◌̃ / |
ṉ | n | U+06BA U+0658 |
32a | 33 | |
| واؤ wāʼo |
و | ـو | /ʋ /, /uː/, /ʊ /, /o ː /, /ɔː / |
v, ū, u, o, au |
w, ū, u, o, au |
U+0648 | 33 | 33 | 34 | ||
| ہے hē |
ہ | ـہ | ـہـ | ہـ | /ɦ/, /ɑː/, /eː/ | h, ā, e | h, ā, e | U+06C1 |
34 | 34 | 35 |
| چھوٹی ہے choṭī hē |
34a | ||||||||||
| دو چشمی ہے do-cashmī hē |
ھ | ـھ | ـھـ | ھـ | /ʰ/ or /ʱ/ |
h | h | U+06BE | 35 | 34b | 36 |
| یے yē |
ی | ـی | ـیـ | یـ | /j/, /iː/, /ɑː/ | y, ī, á | y, ī, á | U+06CC | 36 | 35 | 38 |
| بڑی یے baṛī yē |
ے | ـے | /ɛː/, /eː/ |
ai, e | ai, e | U+06D2 | 37 | 35b | 39 | ||
| ہمزہ hamzah |
ئ | ـئ | ـئـ | ئـ | /ʔ/ or silent |
ʼ, –, yi | ʼ, –, yi | U+0626 | 35a | 37 | |
| ء | U+0621 | 0 | |||||||||
- Footnotes:
- dictionary order
- At the beginning of a word it can represent another vowel, holding a vowel diacritic that would normally be held by the consonant preceding the vowel, for examble اُردو "Urdu". But the diacritic indicating which vowel is often omitted اردو like other short vowel diacritcs.
- ^ No Urdu word begins with ں, ھ, ڑ, or ے.
- Used mainly for Persian loanwords.
- The version shown on the left is U+06BA, which is used only at the end of words. When it is used in the middle of a word it is a diacritic U+0658, which is usually omitted (see below for further information on diacritic omission in Urdu).
- Not present in dictionary order because it is not used at the beginning of words.
- Sometimes choṭī hē is used to refer to hey but choṭī hē can also refer to the Arabic / Persian variant, a stylistic variation representing an equivalent letter, but Persian and Arabic usually use U+0647 whereas Urdu uses U+06C1 for gōl hey. See also: Urdu in Unicode.
- Hamzah: In Urdu, hamzah is silent in all its forms except for when it is used as hamzah-e-izafat. The main use of hamzah in Urdu is to indicate a vowel cluster.
Additional characters and variations
Arabic Tāʼ marbūṭah
Tāʼ marbūṭah is also sometimes considered the 40th letter of the Urdu alphabet, though it is rarely used except for in certain loan words from Arabic. Tāʼ marbūṭah is regarded as a form of tā, the Arabic version of Urdu tē, but it is not pronounced as such, and when replaced with an Urdu letter in naturalised loan words it is usually replaced with Gol hē.
Table
| Group | Letter | Name (see: Glossary of key words) | Unicode | |||
|---|---|---|---|---|---|---|
| Nastaliq |
Naskh with diacritics |
Roman Urdu or English | ||||
| Alif | آ | آ | الف مدہ | الِف مَدّه |
alif maddah |
U+0622 alef with madda above |
| Hamza | ء | ء | ہمزہ | ہَمْزه |
hamzah | U+0621 hamza |
| ___ | ___ | hamza on the line | ||||
| ٔ | ــٔـ | ___ | ___ | hamza diacritic |
U+0654 Hamza Above | |
| ئ | ئ | ہمزہ | ہَمْزه |
hamzah | U+0626 yeh with hamza above | |
| ___ | ___ | yē hamza / alif hamza | ||||
| ۓ | ۓ | ___ | ___ | baṛī yē hamza | U+06D3 yeh barree with hamza above | |
| ؤ | ؤ | واوِ مَہْمُوز | واوِ مَہْمُوز |
vāv-e mahmūz |
U+0624 waw with hamza above | |
| ۂ ۂ | ۂ ـۂ | ___ | ___ | U+06C2 heh goal with hamza above or U+06C1 + U+0654 | ||
| Arabic | ۃ ۃ | ۃ ـۃ | Arabic: تاء مربوطة |
Arabic: تَاء مَرْبُوطَة |
tāʼ marbūṭah "bound ta" |
U+06C3 teh marbuta goal |
| ة ة | ة ـة | U+0629 teh marbuta | ||||
| ت | ت | Arabic: تاء مفتوحة |
Arabic: تَاء مَفْتُوحَة |
tāʼ maftūḥah "open ta" |
U+062A Teh | |
- Footnotes:
- Left: Urdu Nastaliq. Right: Arabic Naskh or modern style.
- The Nastaliq text will display in a different style if there is not an appropriate font installed on the machine.
- ^ Most vowel diacritics are omitted in most Urdu writing, but Urdu writing usually does distinguish alif mad, and include hamza over bari ye, gol he, and wow. For example, alif mad and bare alif in آزادی - "āzādī", ɑ:zɑ:d̪i, freedom
- are distinguished in most contexts. - See: Hamzah in Nastaliq.
- See: Hamzah in Nastaliq.
- see: Arabic Tāʼ marbūṭah above.
Hamza in Nastaliq
Hamza can be difficult to recognise in Urdu handwriting and fonts designed to replicate it, closely resembling two dots above as featured in ت Té and ق Qaf, whereas in Arabic and Geometric fonts it is more distinct and closely resembles the western form of the numeral 2 (two).
Digraphs
| Digraph | Transcription | IPA | Examples |
| بھ | bh | بھاری | |
| پھ | ph | پھول | |
| تھ | th | تھیلا | |
| ٹھ | ṭh | ٹھنڈا | |
| جھ | jh | جھاڑی | |
| چھ | chh | چھتری | |
| دھ | dh | دھوبی | |
| ڈھ | ḍh | ڈھول | |
| رھ | rh | تیرھواں | |
| ڑھ | ṛh | اڑھائی | |
| کھ | kh | کھانسی | |
| گھ | gh | گھوڑا | |
| لھ | lh | دولھا (alternative of دُلہا) | |
| مھ | mh | تمھیں | |
| نھ | nh | ننھا |
A separate do-chashmi-he letter, ھ, exists to denote a /ʰ/ or a /ʱ/. This letter is mainly used as part of the multitude of digraphs, detailed in above.
Differences from Persian alphabet
Urdu has more letters added to the Perso-Arabic base to represent sounds not present in Persian, which already has additional letters added to the Arabic base itself to represent sounds not present in Arabic. The letters added are shown in the table below:
| Letter | IPA |
|---|---|
| ٹ | /ʈ/ |
| ڈ | /ɖ/ |
| ڑ | /ɽ/ |
| ں | /◌̃/ |
| ے | /ɛ:/ or /e:/. |
Retroflex letters

Old Hindustani used four dots ٿ ڐ ڙ over three Arabic letters ت د ر to represent retroflex consonants. In handwriting those dots were often written as a small vertical line attached to a small triangle. Subsequently, this shape became identical to a small letter ط t̤oʼē. It is commonly and erroneously assumed that ṭāʾ itself was used to indicate retroflex consonants because of it being an emphatic alveolar consonant that Arabic scribes thought approximated the Hindustani retroflexes. In modern Urdu, called to'e is always pronounced as a dental, not a retroflex.
Vowels
The Urdu language has ten vowels and ten nasalized vowels. Each vowel has four forms depending on its position: initial, middle, final and isolated. Like in its parent Arabic alphabet, Urdu vowels are represented using a combination of digraphs and diacritics. Alif, Waw, Ye, He and their variants are used to represent vowels.
Vowel chart
Urdu does not have standalone vowel letters. Short vowels (a, i, u) are represented by optional diacritics (zabar, zer, pesh) upon the preceding consonant or a placeholder consonant (alif, ain, or hamzah) if the syllable begins with the vowel, and long vowels by consonants alif, ain, ye, and wa'o as matres lectionis, with disambiguating diacritics, some of which are optional (zabar, zer, pesh), whereas some are not (madd, hamzah). Urdu does not have short vowels at the end of words. This is a table of Urdu vowels:
| Romanization | Pronunciation | Final | Middle | Initial |
|---|---|---|---|---|
| a | /ə/ | N/A | ـَ | اَ |
| ā | /aː/ | ـَا، ـَی، ـَہ | ـَا | آ |
| i | /ɪ/ | N/A | ـِ | اِ |
| ī | /iː/ | ـِى | ـِیـ | اِیـ |
| e | /eː/ | ـے | ـیـ | ایـ |
| ai | /ɛː/ | ـَے | ـَیـ | اَیـ |
| u | /ʊ/ | N/A | ـُ | اُ |
| ū | /uː/ | ـُو | اُو | |
| o | /oː/ | ـو | او | |
| au | /ɔː/ | ـَو | اَو | |
Alif
Alif is the first letter of the Urdu alphabet, and it is used exclusively as a vowel. At the beginning of a word, alif can be used to represent any of the short vowels: اب ab, اسم ism, اردو Urdū. For long ā at the beginning of words alif-mad is used: آپ āp, but a plain alif in the middle and at the end: بھاگنا bhāgnā.
Wāʾo
Wāʾo is used to render the vowels "ū", "o", "u" and "au" (, , and respectively), and it is also used to render the labiodental approximant, . Only when preceded by the consonant k͟hē (خ), can wāʾo render the "u" () sound (such as in خود, "k͟hud" - myself), or not pronounced at all (such as in خواب, "k͟haab" - dream). This is known as the silent wāʾo, and is only present in words loaned from Persian.
Ye
Ye is divided into two variants: choṭī ye ("little ye") and baṛī ye ("big ye").
Choṭī ye (ی) is written in all forms exactly as in Persian. It is used for the long vowel "ī" and the consonant "y".
Baṛī ye (ے) is used to render the vowels "e" and "ai" (/eː/ and /ɛː/ respectively). Baṛī ye is distinguishable in writing from choṭī ye only when it comes at the end of a word/ligature. Additionally, Baṛī ye is never used to begin a word/ligature, unlike choṭī ye.
| Letter's name | Final Form | Middle Form | Initial Form | Isolated Form |
|---|---|---|---|---|
| چھوٹی يے Choṭī ye |
ـی | ـیـ | یـ | ی |
| بڑی يے Baṛī ye |
ـے | ے |
The 2 he's
He is divided into two variants: gol he ("round he") and do-cašmi he ("two-eyed he").
Gol he (ہ) is written round and zigzagged, and can impart the "h" (/ɦ/) sound anywhere in a word. Additionally, at the end of a word, it can be used to render the long "a" or the "e" vowels (/ɑː/ or /eː/), which also alters its form slightly (on modern digital writing systems, this final form is achieved by writing two he's consecutively).
Do-cašmi he (ھ) is written as in Arabic Naskh style (as a loop), in order to create the aspirate consonants and write Arabic words.
| Letter's name | Final Form | Middle Form | Initial Form | Isolated Form |
|---|---|---|---|---|
| گول ہے Gol he |
ـہ | ـہـ | ہـ | ہ |
| دو چشمی ہے Do-cašmi he |
ـھ | ـھـ | ھـ | ھ |
Ayn
Ayn in its initial and final position is silent in pronunciation and is replaced by the sound of its preceding or succeeding vowel.
Nun Ghunnah
Vowel nasalization is represented by nun ghunna written after their non-nasalized versions, for example: ہَے when nasalized would become ہَیں. In middle form nun ghunna is written just like nun and is differentiated by a diacritic called maghnoona or ulta jazm which is a superscript V symbol above the ن٘.
Examples:
| Form | Urdu | Transcription |
| Orthography | ں | ṉ |
| End form | میں | maiṉ |
| Middle form | کن٘ول | kaṉwal |
Diacritics
Urdu uses the same subset of diacritics used in Arabic based on Persian conventions. Urdu also uses Persian names of the diacritics instead of Arabic names. Commonly used diacritics are zabar (Arabic fatḥah), zer (Arabic kasrah), pesh (Arabic dammah) which are used to clarify the pronunciation of vowels, as shown above. Jazam (ـْـ, Arabic sukun) is used to indicate a consonant cluster and tashdid (ـّـ, Arabic shaddah) is used to indicate a gemination, although it is never used for verbs, which require double consonants to be spelled out separately. Other diacritics include khari zabar (Arabic dagger alif), do zabar (Arabic fathatan) which are found in some common Arabic loan words. Other Arabic diacritics are also sometimes used though very rarely in loan words from Arabic. Zer-e-izafat and hamzah-e-izafat are described in the next section.
Other than common diacritics, Urdu also has special diacritics, which are often found only in dictionaries for the clarification of irregular pronunciation. These diacritics include kasrah-e-majhool, fathah-e-majhool, dammah-e-majhool, maghnoona, ulta jazam, alif-e-wavi and some other very rare diacritics. Among these, only maghnoona is used commonly in dictionaries and has a Unicode representation at U+0658. Other diacritics are only rarely written in printed form, mainly in some advanced dictionaries.
Iẓāfat
Iẓāfat is a syntactical construction of two nouns, where the first component is a determined noun, and the second is a determiner. This construction was borrowed from Persian. A short vowel "i" is used to connect these two words, and when pronouncing the newly formed word the short vowel is connected to the first word. If the first word ends in a consonant or an ʿain (ع), it may be written as zer ( ِ ) at the end of the first word, but usually is not written at all. If the first word ends in choṭī he (ہ) or ye (ی or ے) then hamzā (ء) is used above the last letter (ۂ or ئ or ۓ). If the first word ends in a long vowel (ا or و), then a different variation of baṛī ye (ے) with hamzā on top (ئے, obtained by adding ے to ئ) is added at the end of the first word.
| Forms | Example | Transliteration | Meaning |
|---|---|---|---|
| ـ◌ِ | شیرِ پنجاب | sher-e-Panjāb | the lion of Punjab |
| ۂ | ملکۂ دنیا | malikā-e-dunyā | the queen of the world |
| ئ | ولئ کامل | walī-e-kāmil | perfect saint |
| ـئے | مئے عشق | mai-e-ishq | the wine of love |
| ئے | روئے زمین | rū-'e-zamīn | the surface of the Earth |
| صدائے بلند | sadā-'e-buland | a high voice |
Computers and the Urdu alphabet
In the early days of computers, Urdu was not properly represented on any code page. One of the earliest code pages to represent Urdu was IBM Code Page 868 which dates back to 1990. Other early code pages which represented Urdu alphabets were Windows-1256 and MacArabic encoding both of which date back to the mid-1990s. In Unicode, Urdu is represented inside the Arabic block. Another code page for Urdu, which is used in India, is Perso-Arabic Script Code for Information Interchange. In Pakistan, the 8-bit code page which is developed by National Language Authority is called Urdu Zabta Takhti (اردو ضابطہ تختی) (UZT) which represents Urdu in its most complete form including some of its specialized diacritics, though UZT is not designed to coexist with the Latin alphabet.
Encoding Urdu in Unicode
| Characters in Urdu |
Characters in Arabic |
|---|---|
| ہ (U+06C1) ھ (U+06BE) |
ه (U+0647) |
| ی (U+06CC) | ى (U+0649) ي (U+064A) |
| ک (U+06A9) | ك (U+0643) |
Like other writing systems derived from the Arabic script, Urdu uses the 0600–06FF Unicode range. Certain glyphs in this range appear visually similar (or identical when presented using particular fonts) even though the underlying encoding is different. This presents problems for information storage and retrieval. For example, the University of Chicago's electronic copy of John Shakespear's "A Dictionary, Hindustani, and English" includes the word 'بهارت' (bhārat "India"). Searching for the string "بھارت" returns no results, whereas querying with the (identical-looking in many fonts) string "بهارت" returns the correct entry. This is because the medial form of the Urdu letter do chashmi he (U+06BE)—used to form aspirate digraphs in Urdu—is visually identical in its medial form to the Arabic letter hāʾ (U+0647; phonetic value /h/). In Urdu, the /h/ phoneme is represented by the character U+06C1, called gol he (round he), or chhoti he (small he).
In 2003, the Center for Research in Urdu Language Processing (CRULP)—a research organisation affiliated with Pakistan's National University of Computer and Emerging Sciences—produced a proposal for mapping from the 1-byte UZT encoding of Urdu characters to the Unicode standard. This proposal suggests a preferred Unicode glyph for each character in the Urdu alphabet.
Software
The Daily Jang was the first Urdu newspaper to be typeset digitally in Nastaʻliq by computer. There are efforts underway to develop more sophisticated and user-friendly Urdu support on computers and on the Internet. Nowadays, nearly all Urdu newspapers, magazines, journals and periodicals are composed on computers via various Urdu software programmes, the most widespread of which is InPage Desktop Publishing package. Microsoft has included Urdu language support in all new versions of Windows and both Windows Vista and Microsoft Office 2007 are available in Urdu through Language Interface Pack support. Most Linux Desktop distributions allow the easy installation of Urdu support and translations as well. Apple implemented the Urdu language keyboard across Mobile devices in its iOS 8 update in September 2014.
Romanization standards and systems
Main article: Roman UrduThere are several romanization standards for writing Urdu with the Latin alphabet, though they are not very popular because most fall short of representing the Urdu language properly. Instead of standard romanization schemes, people on Internet, mobile phones and media often use a non-standard form of romanization which tries to mimic English orthography. The problem with this kind of romanization is that it can only be read by native speakers, and even for them with great difficulty. Among standardized romanization schemes, the most accurate is ALA-LC romanization, which is also supported by National Language Authority. Other romanization schemes are often rejected because either they are unable to represent sounds in Urdu properly, or they often do not take regard of Urdu orthography, and favor pronunciation over orthography.
The National Language Authority of Pakistan has developed a number of systems with specific notations to signify non-English sounds, but these can only be properly read by someone already familiar with the loan letters.
Roman Urdu also holds significance among the Christians of Pakistan and North India. Urdu was the dominant native language among Christians of Karachi and Lahore in present-day Pakistan and Madhya Pradesh, Uttar Pradesh Rajasthan in India, during the early part of the 19th and 20th century, and is still used by Christians in these places. Pakistani and Indian Christians often used the Roman script for writing Urdu. Thus Roman Urdu was a common way of writing among Pakistani and Indian Christians in these areas up to the 1960s. The Bible Society of India publishes Roman Urdū Bibles that enjoyed sale late into the 1960s (though they are still published today). Church songbooks are also common in Roman Urdu. However, the usage of Roman Urdu is declining with the wider use of Hindi and English in these states.
Glossary of key words from letter names
| Letter name(s) | Urdu word | Examples of other uses | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Isolated form |
Urdu name |
Roman Urdu | Urdu | IPA | Roman Urdu name |
English Translation | Urdu | Roman Urdu or IPA | Translation |
| ح | بَڑی حے | baṛī ħē | بَڑی | bəɽi | baṛī / bari |
big / elder | بڑی آنت | Baṛi ant | large intestine |
| ے | بَڑی يـے | baṛī yē | آنت | Ant | intestine | ||||
| ی | چھوٹی یے | čhōṭī yē | چھوٹی | tʃʰoːʈi | choti | small / minor / junior | |||
| ہ | چھوٹی ہے | čhōṭī hē | چھوٹی آنت | small intestine | |||||
| گول ہـے | gōl hē | گول | goːl | gōl | round / spherical / vague / silly / obese | گول گپے | gol gappay | panipuri | |
| ھ | دوچَشْمی ہے | dō-čašmī hē | دوچَشْمی | do-cashmī | two-eyed |
دو چشمی دوربین | do-cashmi
dorabīn |
binoculars | |
| دوربین | dorabīn | telescope | |||||||
| دو | do | 2 / two | دو ایوانیت | do ayvanīt | bicameralism | ||||
| چشم | /tʃəʃm/ | chashm | the eye / hope / expectation | چشم | cashm | eye | |||
| ں | نُونِ غُنّہ | nūn-e ğunnah | غُنّہ | ɣʊnnɑ | ğunnah / g͟hunnah | nasal sound or twang | |||
| آ | الِف مَدّه | alif maddah | مَدّه | maddah | Arabic: | ||||
| ؤ | واوِ مَہْمُوز | vāv-e mahmūz | مَہْمُوز | mæhmuːz | mahmūz | defective / improper | |||
| ء ا آ ب پ ت ٹ ث ب ج چ خ ح د ڈ ذ ر ڑ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ل م ن ں و ہ ھ ی ے | حروف تہجی |
harūf tahajī (alphabet) | تہجی | tahajī | sequence |
||||
| حُرُوف | /hʊruːf/ | harūf | letters (plural) (often referred to as "alphabets" in informal Pakistani English) |
||||||
| حَرْف | /hərf/ | harf | "letter of the alphabet" / handwriting / statement / blame / stigma | ||||||
See also
- Nastaʻliq script
- Romanization of Urdu
- Urdu Braille
- Urdu Informatics
- Urdu keyboard
- Urdu Misplaced Pages
References
- "Constitution of the Republic of South Africa, 1996 – Chapter 1: Founding Provisions". gov.za. Retrieved 6 December 2014.
- "Balti alphabet and pronunciation". omniglot.com. Retrieved 31 January 2023.
- Bashir, Elena; Hussain, Sarmad; Anderson, Deborah (5 May 2006). "N3117: Proposal to add characters needed for Khowar, Torwali, and Burushaski" (PDF). ISO/IEC JTC1/SC2/WG2.
- ^ Project Fluency (7 October 2016). Urdu: The Complete Urdu Learning Course for Beginners: Start Speaking Basic Urdu Immediately (Kindle ed.). Createspace Independent Publishing Platform. p. Kindle Locations 66–67. ISBN 978-1-5390-4780-3.
- ^ "Urdu". Omniglot.
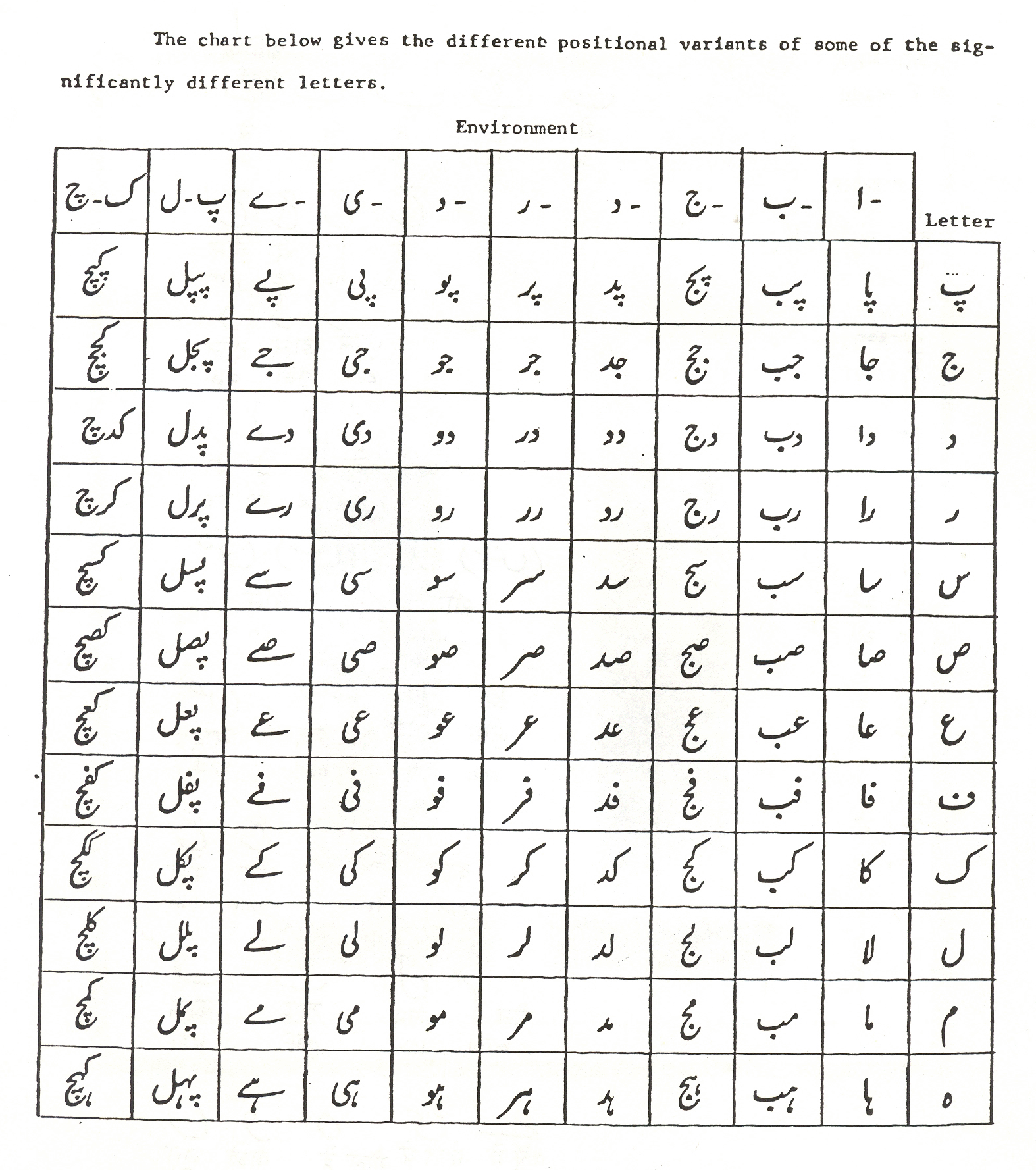
- "*positional chart*". Urdu: some thoughts about the script and grammar, and other general notes for students. Retrieved 28 February 2020 – via www.columbia.edu.
- "Controversy over number of letters in Urdu alphabet". DAWN.COM. 15 June 2009.
- Delacy 2003, pp. XV–XVI.
- ^ "Urdu romanization" (PDF). The Library of Congress.
- Geographical Names Romanization in Pakistan. UNGEGN, 18th Session. Geneva, 12–23 August 1996. Working Papers No. 85 and No. 85 Add. 1.
- Bhatia, Tej K.; Khoul, Ashok; Koul, Ashok (2015). Colloquial Urdu: The Complete Course for Beginners. Routledge. pp. 41–42. ISBN 978-1-317-30471-5. Retrieved 30 June 2020.
- ^ "Urdu Alphabet". www.user.uni-hannover.de. Archived from the original on 11 September 2019. Retrieved 29 February 2020.
- ^ "Extended Arabic Letter". unicode.org. Retrieved 6 April 2020.
- ^ "Based on ISO 8859-6". unicode.org. Retrieved 6 April 2020.
- ^ "Urdu: Oxford Living Dictionaries". Urdu: Oxford Living Dictionaries. Archived from the original on 18 October 2016. Retrieved 15 March 2020.
- Ballantyne, James Robert (1842). A Grammar of the Hindustani Language, with Brief Notices of the Braj and Dakhani Dialects. Madden & Company. p. 11.
- Berggren, Olaf (2002). Scripts. Bibliotheca Alexandrina. p. 108.
- Grierson, George Abraham. "Urdu Language Management". Language Information Services (LIS)-India. Retrieved 23 July 2022.
- "Proposal of Inclusion of Certain Characters in Unicode" (PDF).
- Delacy 2003, pp. 99–100.
- "IBM 868 code page"
- "Urdu Zabta Takhti" (PDF).
- "Arabic" (PDF). unicode.org. Retrieved 7 April 2019.
- "A dictionary, Hindustani and English". Dsal.uchicago.edu. 29 September 2009. Retrieved 18 December 2011.
- "A dictionary, Hindustani and English". Dsal.uchicago.edu. Archived from the original on 15 December 2012. Retrieved 18 December 2011.
- "Center for Research in Urdu Language Processing". Crulp.org. Retrieved 18 December 2011.
- Archive index at the Wayback Machine
- "مائِیکروسافٹ ڈاؤُن لوڈ مَرکَزWindows". Microsoft.com. Retrieved 18 December 2011.
- "Ubuntu in Urdu « Aasim's Web Corner". Aasims.wordpress.com. Retrieved 18 December 2011.
- "E-Urdu: How one man's plea for Nastaleeq was heard by Apple". The Express Tribune. 16 October 2014. Retrieved 29 March 2015.
- "اردو میں نقل حرفی ۔ ایک ابتدائی تعارف: نبلٰی پیرزادہ". nlpd.gov.pk.
- ^ "Urdu: Oxford Living Dictionaries (Urdu to English Translation)". Urdu: Oxford Living Dictionaries. Retrieved 15 March 2020.
- "خلا سے زمین پر انگریزی کےحروف تہجی". BBC News اردو (in Urdu). 5 January 2016. Retrieved 7 May 2020.
{kind=link}
Sources
- Delacy, Richard (2003). Beginner's Urdu Script. McGraw-Hill.
- Delacy, Richard (2010). Read and write Urdu script. McGraw-Hill. ISBN 978-0-07-174746-2.
- "Urdu romanization" (PDF). The Library of Congress.
- Ishida, Richard. "Urdu script notes".
External links
- Urdu alphabet
- Urdu alphabet with Devanagari equivalents. Archived 11 September 2019 at the Wayback Machine.
- Hugo's Urdu Alphabet Page. Archived 16 July 2020 at the Wayback Machine.
- calligraphyislamic.com, a resource for Urdu calligraphy and script
- Urdu Script Introduction from Columbia University
- National Council for Promotion of Urdu Language. Archived 6 March 2018 at the Wayback Machine.
| Urdu | |||||
|---|---|---|---|---|---|
| Varieties |
| ||||
| Politics | |||||
| Arts | |||||
| Languages of Pakistan | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Official languages | |||||||||||||
| Other languages (by administrative unit) |
| ||||||||||||
| Related topics | |||||||||||||